
LinkedIn is the largest professional network in the world, a treasure trove of data for a variety of customer-facing stakeholders, including sales teams, marketers, recruiters, and researchers. Imagine the access you have to detailed information on millions of professionals and companies, all at your fingertips.
It would be impractical to manually collect this information. That’s where web scraping comes in. It takes the data update burden out of the equation, saving you time and delivering impactful information.
That said, scraping LinkedIn isn’t just about pointing a tool at the site and going. The platform has a lot of protections to prevent automated access. I’m going to show you how to web scrape LinkedIn as effectively and responsibly as possible. We’ll talk about the tools, techniques, and best practices to scrape the information that you desire, all while making sure that you fly beneath the radar and respect LinkedIn.
There are a number of methods available, including specialized scraping tools, custom-built scripts, and much more. However, it is really important to know what it means to scrape when it comes to LinkedIn’s rules. Scraping information that is publicly available is generally acceptable. Still, you do not want to engage in aggressive or excessive scraping, as this can result in permanent restrictions or account bans.
Table of Contents
What Is LinkedIn Web Scraping and Why Use It?
LinkedIn web scraping is the automated extraction of data from LinkedIn pages. A “scraper” or “bot” will systematically navigate through a set of profiles, company pages, or job postings, copying relevant information and putting that information into a structured format such as a spreadsheet or a database.
It is as if a super-fast research assistant is scanning through thousands of pages in the same time that it would take you to scan through a few dozen pages.
What’s the possible use for this? The use cases are incredibly varied and all very powerful.
- Lead Generation: Sales and marketing teams can build highly targeted lead lists. You could scrape the profiles of professionals who fit your ideal customer profile- either by job title, industry, company size, or even which technologies they mention in their skills. That allows you to have hyper-personalized outreach campaigns that convert much better than generic campaigns.
- Market Research: Interested in understanding the competitive landscape? You can crawl and analyze your competitors’ company pages to see their growth, their hiring patterns, and understand their organizational structure. You can scrape data to better understand quickly developing trends in your industry, the trending skills in your industry, or the geographical distribution of talent.
- Recruitment and Talent Sourcing: Recruiters can go beyond the simple keyword search process to find the ideal candidates. By scraping a person’s profile, it can uncover passive candidates that may not be looking for a job but possess the exact skills and experience required for that role. It’s an excellent way to build a deep talent pipeline. This is useful in instances when you want to know how to scrape LinkedIn jobs for an assessment of the job market.
- Academic Research: Social scientists, economists, and business studies researchers can utilize scraped LinkedIn data to investigate labor market dynamics, patterns of professional migration, the link to educational background, and so much more.
- Contact Information Gathering: Back to the concept of privacy, while scraping can be a horrible way to compromise the privacy of individuals, it can very quickly help you find publicly available contact information, or it could be used to verify the contact data of a list of professional contacts so you can get hold of the correct people.
In essence, if there is data on a publicly available LinkedIn page that is useful for your company (or research), data scraping is a scalable way to compile it.
Read More: Top Web Scraping Software for Data Analysis?
Is It Legal to Scrape LinkedIn Data? A Quick Overview
That is the million-dollar question, and the answer is complex. The distinction is whether or not the conduct is legal or is a violation of LinkedIn’s User Agreement.
From a legal perspective, the only significant case in the U.S. is LinkedIn Corp. v. HiQ Labs Inc., where the two companies disputed HiQ’s scraping of public LinkedIn profiles for years.
The courts have sided with HiQ, and now we have a very important precedent: scraping public data from the internet is not a violation of the Computer Fraud and Abuse Act (CFAA). The rationale for the verdict is if data is visible on the web to all without a password, it is not “protected” in the sense that the CFAA intends.
However, this does not mean it’s a free-for-all.
- Violation of Terms of Service: LinkedIn’s User Agreement clearly states that using “bots” or any automated methods to access and scrape LinkedIn is prohibited. By creating a LinkedIn account, you accept those terms. If LinkedIn determined that you are scraping, they could absolutely prevent your usage, suspend your account, or terminate your account entirely.
- Copyright: Although individual pieces of information (e.g., a person’s job title) may be copyright-free, LinkedIn may have copyright on the data for a compilation, although this is a grey area.
- Data Privacy Laws: If you are scraping people’s data, and especially people in the EU, you must understand laws like GDPR. The data you are processing has to be handled responsibly, safely stored, and you must have a lawful basis for processing it.
Disclaimer: This is for educational purposes only, not legal advice. You should seek advice from a lawyer with knowledge of your circumstances and jurisdiction.
So, as I said above, scrapers can be legally defensible regarding scraping public data from LinkedIn, but this does violate their policies. Therefore, most of this article focuses on the technical side of things – how to do it while avoiding being caught.
Scrape LinkedIn public search results
If you need publicly visible LinkedIn search results (e.g., names, headlines, profile URLs surfaced by a search engine), prioritize compliant sources and methods:
- Prefer search-engine results (e.g., Bing, Google) with
site:linkedin.comfilters, accessed via their official APIs. - Avoid automating LinkedIn’s site directly; it likely violates the Terms of Service.
- Collect only data that’s already public, respect robots/exclusions, throttle requests, and provide opt-out paths.
Public search results: Snippets and URLs that search engines display from LinkedIn pages that are publicly indexable. Think: a person or company page that appears in Bing/Google with a title, meta description, and link.
Not included: Content behind logins, paywalls, rate-limited views, or anything gated. Automating LinkedIn’s UI (headless browsers, session cookies) is risky and typically against LinkedIn’s TOS.
LinkedIn user agreement scraping automated means prohibited
Here’s the key point in plain terms:
- LinkedIn prohibits scraping, crawling, or using automated means to access, copy, or collect data from its platform.
- This includes profiles, connections, and any other content on LinkedIn, whether for commercial use, academic research, or lead generation.
- The restriction applies even if the data is “publicly visible” once you’re logged in — automated extraction directly from LinkedIn’s site or apps violates their Terms of Service.
Example clause (summarized):
You agree not to “scrape, copy, or collect information of others through automated means (such as bots, crawlers, spiders, or scrapers) without LinkedIn’s explicit permission.”
Why it matters
- LinkedIn actively enforces this — with technical defenses (CAPTCHAs, throttling), legal actions (they’ve sued scraping companies), and account suspensions.
- Even if you don’t log in, automating against their site (HTML scraping) falls under “unauthorized automated means.”
Choosing the Right Data to Scrape: What’s Valuable on LinkedIn?
Before considering constructing or using a scraper, make sure you have a well-thought-out strategy. What exactly is it you want to scrape? Scraping information indiscriminately is unnecessary, costs you time, and increases your chances of being detected. LinkedIn has a vast ocean of information to explore (i.e., “Where is the treasure buried?”)
The relevant data on LinkedIn Profiles
Profiles are at the centre of LinkedIn. Below is a list of the most relevant Identifiers, data points that you can extract:
- Full Name: The most basic identifier.
- Job Title / Headline: Important to your understanding of a person’s role and professional identity.
- Current Company & Location: Relevant for lead generation, recruiting, and market analysis.
- Work Experience: A complete account of previous roles, companies, and duration, allowing the building of a career trajectory.
- Education: Information about universities, degrees, and areas of study.
- Skills & Endorsements: A good source of information on experts in various technologies, software, or methodologies.
- Recommendations: Qualitative information about a person’s work ethic and standing in the profession.
- Connections Count: A rough measure of the size of a person’s network and influence.
- Profile URL: The unique link to the page that is the source of your data.
Valuable Data on LinkedIn Company Pages
Company pages are rich repositories of organizational information that have real value in B2B sales, competitive intelligence, and investment analysis.
- Company Name & Description: company name and a mission statement.
- Industry: How the company describes itself (e.g., “Information Technology & Services”).
- Company Size / Number of Employees: an important criterion when filtering companies to target.
- Headquarters Location: the company’s primary physical address.
- Website URL: a direct link to the company’s website.
- Employees: a link to the search results to show all LinkedIn profiles of employees associated with the company, which provides an analysis starting point at a minimum.
- Recent Updates: This may be the company’s most recent posts, which provide insight into what they have recently done, whether that is product launches, internal launches, or company culture posts.
- Job Availability: This allows you a direct review of their employment needs and potential growth areas.
By first defining which of these data points relate to your goals, it is possible to configure your scraper to be more efficient and create more focused information that you will collect.
LinkedIn API vs Scraping: Which One Should You Use?
LinkedIn does provide an official API for developers. So why would you want to have the hassle of web scraping linkedin?
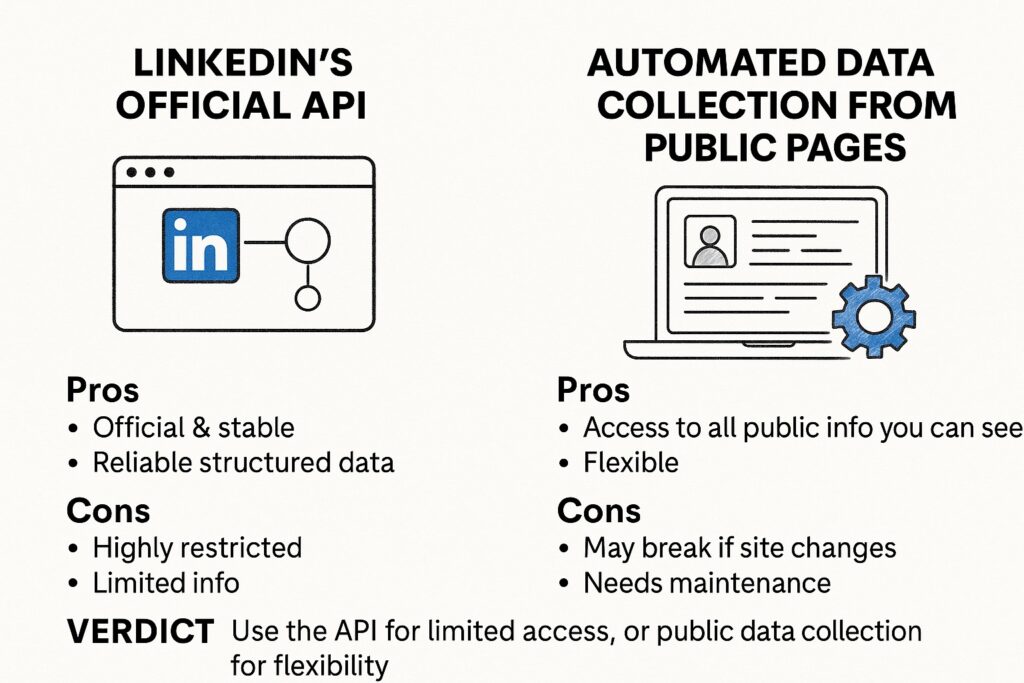
The Official LinkedIn API
The official API is meant for building applications that integrate with LinkedIn. For example, allowing users to authenticate via “Sign in with LinkedIn” or share content from an app to their feed.
- Pros:
- Official and Reliable: It’s the approved way of getting data, so you don’t have to worry about getting banned for using it.
- Data Format: The API provides you with data that is cleanly defined and structured in acceptable formats. The structure of the information shouldn’t change randomly and unexpectedly.
- Cons:
- Truly Limited: This is the biggest problem. LinkedIn has strict restrictions in place against its API. For the reasons we have mentioned already, it is extremely difficult for most organizations to get authorized to utilize function permissions that would give them access to profile-level or company-level data.
- Limited Set of Data: Accompanied by limitations of authorization, access to a very small subset of information available under the site is available via the API. For any Pricing, usually you cannot get a lot of information, like detailed work experience, skills, or lists of employees.
- Rate Limits: The API follows strict rate limits on the overall requests you can make in a certain timeframe.
Web Scraping linkedin
web scraping LinkedIn, as noted, automates a browser to get you the data directly from the website.
- Pros
- Full Access to All Public Data: If you can see it in your browser while logged in, you can scrape it; this means you can get details on profiles, company pages, job listings, and more.
- Control: You have control over what data you get and how you get it.
- Cons
- Against Terms of Service: There is a risk to your account being suspended.
- Fragile: Scrapers can break when LinkedIn makes a change to its website layout.
- Work: You must take full responsibility for all the anti-blocking measures.
The Verdict
- Use the API if… You are developing an application that requires basic profile information for authentication (r_liteprofile) or sharing, and you can obtain the appropriate partner program approval.
- Use Scraping if… You need rich, detailed data at scale for lead generation, market research, or recruitment purposes. For most data-heavy business cases, scraping is, pragmatically, the only feasible method.
Tools You Can Use to Scrape LinkedIn Effectively
There is no “best” tool for scraping LinkedIn. The right choice really comes down to your technical skill, budget, and the size of your project. Most tools for scraping LinkedIn fall into three main categories.
1. Browser Extensions
These are very easy to start using. Browser extensions install directly into your web browser (Chrome or Firefox), and generally provide a point-and-click interface for the extraction experience. You navigate to a LinkedIn page, turn on the extension, and it scrapes any data off the page you’re looking at.
- Advantages: Easy to use, no coding experience needed, and good for small, one-off scraping tasks.
- Disadvantages: Not very scalable (often manual), higher chance of being detected because the scraper is working in a logged-in browser session, and less customization.
- Best for: Salespeople who just need to quickly grab data from a few dozen profiles, or if you are someone who just wants a quick list and does not need to set anything technical up.
2. No-Code data Scraping Tools
These are desktop or cloud-based software programs that provide visual interfaces for building scrapers. You can often “train” these tools on how to traverse a site and what data to collect; you do not have to build any code. These can also accommodate more complex logic, such as pagination, and can be run on a schedule.
- Pros: More powerful and scalable than extensions, allow more complex scenarios, and sometimes have built-in features to help avoid blocking.
- Cons: May have a slightly steeper learning curve than extensions, and usually charge subscription fees.
- Best for: Marketing teams, startups, and companies that want or need to collect data on a regular basis but don’t have access to dedicated developers. If you research and find a powerful Linkedin Profile Scraper or one that will scrape a LinkedIn Company scraper, that will be a valuable asset.
LinkedIn Profile Scraper - Profile Data
Discover everything you need to know about LinkedIn Profile Scraper , including its features, benefits, and the different options available to help you extract valuable professional data efficiently.
3. Custom Scripts (Python)
When it comes to power, flexibility, and scale, nothing beats writing your own scraper. Python is the go-to language for data scraping because of its amazing libraries. Therefore, learning how to scrape LinkedIn data using Python is a valuable skill:
- Important Libraries:
- Requests: Used to make HTTP requests to retrieve the raw HTML of a page (works best for static pages).
- Beautiful Soup: A library for parsing HTML and XML documents. It creates a parse tree from the source code of the page that can be used to extract data.
- Selenium / Playwright: Both are browser automation tools. They control a real browser (e.g., Chrome, Firefox) so they can render JavaScript, click buttons, fill out forms, and scroll down the page. Selenium, or Playwright, will be needed for robust scraping on LinkedIn because it is a very dynamic website that relies heavily on JavaScript.
- Pros: Full control over every aspect of the operation, ultimate scalability, most cost effective (no subscriptions in the long run).
- Cons: Coding knowledge required, longer set-up time, you will be personally managing everything including use of proxy sites and anti-blocking measures.
- Best for: Developers, data scientists and companies with technical teams looking for large amounts of narrow data.
Many advanced users will use a linkedin scraping API. They do all the heavy lifting for you, including proxies, browser management, and parsing of the configured data, and just give you the clean, structured data you want through an API call. A good halfway house that combines the usability of a tool and the flexibility of a custom solution.
Step-by-Step Guide: How to Web Scrape LinkedIn Profiles
Let’s follow a hypothetical process to scrape LinkedIn profiles using a no-code visual scraping tool since that can often be a good middle ground between power and accessibility. The principles will apply in whatever manner you decide to choose.
Goal: We want to get a list of “Marketing Managers” in “Berlin, Germany” along with their name, headline and current company.
Step 1: Setup / Authentication
First, we will need to authenticate. Scraping LinkedIn while not being logged in will only show you very limited, public versions of profiles. To get the full profiles, you will need your scraper to operate within a logged-in session. Most tools and scripts have ways to use your session cookies.
- Make sure to log in to your LinkedIn account in a standard browser. Use a browser extension like “EditThisCookie” to export your li_at (authentication) cookie. You will give the li_at cookie to your scraping tool so that it can make authenticated requests on your behalf. Just a reminder: keep your li_at cookie a secret like your password!
Step 2: Define the Starting Point
Your scraper must have an initial location to start scraping. It’s best if you use LinkedIn’s search function to find you a location to start at.
- Action: Go to LinkedIn, and search for “Marketing Manager.” Filter the results by “People” and then filter again by location “Berlin, Germany.” You will copy the link from the address bar of your browser. It will look like: https://www.linkedin.com/search/results/people/?keywords=Marketing%20Manager&origin=GLOBAL_SEARCH_HEADER&sid=XYZ. This is your starting URL.
Step 3: Configure the Scraper to Navigate
Next, you’ll need to teach the scraper how to get from the search results page to the individual profiles, as well as how to get from one page of results to the next.
- Looping Through Profiles: Typically, in a visual scraping tool, you will issue a “Select” command to click each profile link in the list of now prepared results. Then, you will be able to loop this Select so that the scraper performs a consistent set of actions on every profile before moving to the next one.
- Dealing with Pagination: Often, one search will return dozens of pages and your activity will need to identify the “Next” button at the bottom of the page, you need to establish a rule for the scraper to click this button after it is finished scraping all the profiles on the current page, and stop once the “Next” button is no longer active.
Step 4: Extract the Data from Each Profile
This is the part of the whole operation. Once the scraper is on profile page, you illustrate what to pull.
- Action: With the tool’s point-and-click mode you’ll select the page elements you want to pull.
- Click on the person’s name. The tool generates a CSS Selector or an XPath for that element. Label this data point “FullName.”
- Click on the person’s headline (for example, “Marketing Manager at Awesome Inc.”). Label this data point “Headline.”
- Click on their current company name in the experience section. Label this data point “CurrentCompany.”
- Click on their location. Label this data point “Location.”
Your tool will now apply those extraction rules automatically and extract each one when it visits the next profile.
Step 5: Run the Scrape and Export
With everything set up now, we can actually run the process.
- Action: Start the scraper. You’ll be able to see it in action (or you can check the log) as it goes through the steps taken to get to the search URL, clicks on the first profile, scrapes the data, goes back and clicks on the second profile, etc. When it finishes with page one, it will click “Next” and so on.
- Export: When the scraping is complete, you can export the scraped data. The typical options are CSV, JSON, or Excel. Now you will have a spreadsheet with columns for “FullName,” “Headline,” and “CurrentCompany” for all of the marketing managers in Berlin.
This cyclical process is the basis of learning how to web scrape data from linkedin in a systematic and repeatable manner.
How to Extract Company Data from LinkedIn
Scraping company data is a very similar process to scraping profiles, only your target and your data points are different. This is extremely useful for B2B marketing, competitor research, and investment research.
Goal: To scrape a list of “Software” companies located in “United Kingdom” with 11-50 employees, while pulling the name, industry, and employee counts.
Step 1: Perform a company search on LinkedIn
Just as with people, the easiest way to get started is with a filtered search.
- Action: Navigate to the main search bar on LinkedIn, type a broad keyword such as “software” (or just leave blank if you only want to filter the other criteria”), and hit enter. On the search results page, click on the “Companies” filter.
- Apply Filters: Now utilize the “All filters” option to further filter the results. Filter for “United Kingdom” for location, select “11-50 employees” for the company size, and select “Computer Software” for the industry.
- Copy the URL: Once you have the filters applied, copy the URL. This will be the starting point for your Linkedin Company Scraper.
LinkedIn Company Scraper - Company Data
Discover everything you need to know about LinkedIn Company Scraper , including its features, benefits, and the various options available to streamline data extraction for your business needs.
Step 2: Configure Navigation and Data Extraction
The process is almost identical to profile scraping.
- Navigate: Have your scraper loop through each company link on the results page. You can have it respect pagination by selecting the “Next” button and clicking it until there are no more pages.
- Extract: On each company’s “About” page, you will extract the following data points:
- Company Name
- Company Tagline/Description
- Website URL
- Industry
- Company Size (or range, e.g., “11-50 employees”)
- Headquarters
- Specialties (The tags that the company has specified)
Step 3: Run and Export
Now you can launch your scraper. It will systematically visit each company page that meets your criteria, scrape the required information, and put that information in one single dataset. When it finishes, you can simply export your list of companies that you targeted for your sales or research team.
Common Challenges in LinkedIn Scraping
Scraping a complex website, like LinkedIn, is not without its challenges. Here are some common challenges you will face and how to overcome them.
1. Dynamic Content and Infinite Scroll
The Problem: Many parts of LinkedIn do not load at once. Instead, they are loaded dynamically using Javascript as you scroll down the page. Therefore, if your scraper is only able to grab the initial HTML and not the new HTML from the page, it will only scrape initial content on the page – leaving you to feel like you got scammed. This is known as “infinite scroll”.
The Solution:
- Use a Browser Automation Tool: This is where a library, like Selenium or Playwright will come in handy. You can program your script to literally scroll down the page, wait until new content is loaded, and then scrape it. You can use a command to scroll to the bottom of the page, wait a couple seconds, check if page height has increased, and then scroll again until you get through all of the content.
- Finding API Calls: A more advanced technique is to use your browser’s Developer Tools (F12) and look in the Network tab. When you scroll, you will often notice that the website is making a background request (XHR/Fetch requests) to an internal API to grab the next chunk of data! You can sometimes replicate these calls directly in your script which is much faster and more efficient than controlling a full browser.
2. Changing Website Layout
The challenge: LinkedIn is constantly changing its website. The CSS selectors or XPaths that you are using to identify data points (e.g. div.class-name-for-headline) can break overnight and your scraper will stop working.
The Solutions:
- Build Robust Selectors: Avoid selectors that are too specific. For instance, can I find a unique attribute (e.g. if data-testid=”profile-headline”), instead of creating a very long and brittle XPath? These types of elements are less likely to change.
- Routine Maintenance and Checks: This is part of the process – you have to routinely check that your scrapers work correctly, and you need to be able to update your selectors when (not if) they break.
- Error Handling: Include good error handling. Your script should not crash when a selector does not find an element, it should log that error (e.g. “could not find headline on profile URL …”), and move on to the next one.
3. Data Cleaning and Normalization
The Challenge: The data you receive from LinkedIn often has a lot of noise. Locations may appear as “Berlin, Germany,” “Berlin Metropolitan Area,” or simply “Berlin.” Job titles are often inconsistent too, e.g., “VP of Marketing,” or “Vice President, Marketing.”
The Solution:
- Data Cleaning Scripts: Data cleaning is perhaps the most important thing you will need to do once you’ve scraped the data. In order to clean data, you need to write scripts (I think Python is great for this with the Pandas library package). You should be able to normalize location names, clean up job titles using regular expressions, and make sure all formatting is consistent throughout the entire dataset.
When your data is cleaned, it is much easier to analyze and use. The difference between amateur scrapings and a serious, reliable data pipeline is overcoming a lot of these messy issues.
Tips for Avoiding Detection While Scraping LinkedIn
From a technical standpoint, this is the most important aspect of learning how to web scrape LinkedIn successfully. If your account gets banned, that’s a big loss. The goal is to act like a human as much as possible without being detected.
1. Use Quality Proxies
Issue: When you make hundreds of requests to LinkedIn within a short period of time from your one home IP address, you will get blocked almost instantly.
Solution: Use a proxy server. Proxies act as intermediaries, so when you make your request to LinkedIn, the request will come from a different IP address.
- Residential Proxies: The gold standard for scraping sensitive sites such as LinkedIn. Residential proxies use IP addresses that are assigned to real homeowners by ISPs. Therefore, to LinkedIn, traffic coming from a residential proxy looks like traffic coming from an everyday user.
- Datacenter Proxies: These proxies are cheaper than residential proxies, but the source of the IP address is a commercial data center. LinkedIn can easily detect these proxies and is more likely to block them.
- Rotation: You do not want to keep the same proxy IP for long. Your proxy service should allow you to rotate your IP address for every request, or every couple of minutes.
2. Throttle Your Scraping Speed
The Problem: Humans are slow, bots are fast. You cannot look at 100 profiles in 5 minutes. If your scraper does, it is an obvious indication of automation.
The Solution: Be patient! 🙂
- Introduce Random Delays: Have your scraper wait a random time (e.g., between 5 and 15 seconds) between actions such as loading a page and clicking a button. Never use a fixed delay (e.g. always wait 5 seconds) as this is also a machine-like pattern.
- Limit Your Daily Volume: Do not do things like scrape 50,000 profiles in 1 day from a single LinkedIn account. Introduce reasonable daily limits (e.g. 100-200 profiles) and adhere to them. You’re going to be better off getting data slowly and consistently than getting blocked quickly.
3. Use Realistic User Agents
A user agent is simply a string of text that your browser sends to a website to identify itself (for example: “Mozilla/5.0 (Windows NT 10.0; Win64; x64)…”).
Problem: Scraping libraries usually have a default, readily identifiable user agent that is why they are so easily detectable.
Solution: Maintain a list of common real-world user agents by browser and operating system, and have your scraper randomly select a user agent from the list for each session.
4. Mimic Human Behavior
Think about how you’re using LinkedIn. You do not jump from profile to profile, you’re scrolling, you are moving your mouse and spending different amounts of time on other profiles.
- Add “Jitter”: Random mouse movements are a good thing to introduce! 🙂
- Scroll Naturally: You are not going to scroll to the bottom of the page at once. Program your scraper to scroll naturally.
- Vary Actions: You’re not just scraping profiles, think about adding in other actions like viewing the main feed, looking at a company page, or checking notifications to make your action pattern seem less robotic.
5. Handle CAPTCHAs
It’s likely you will eventually hit a CAPTCHA (known as an “I’m not a robot” test).
Solution:
- CAPTCHA Solving Services: There are third-party providers (such as 2Captcha or Anti-CAPTCHA) that can solve CAPTCHAs for you via an API. When your scraper detects a CAPTCHA, it can take a screenshot of the CAPTCHA image and send it to a service, find the solution, and submit the solution via the API.
- Prevention: The best solution is to be so good at the other tips that you rarely see a CAPTCHA at all. Because CAPTCHAs are usually a sign that LinkedIn is already suspicious of you.
By using these methods, you will create a scraping profile that is much harder for LinkedIn’s automated systems to tell apart from a real active human user.
Best Practices for Organizing and Storing Scraped LinkedIn Data
Collecting the information is only half the battle. If you’re not structuring it correctly and saving it appropriately, it is useless.
- Identify the Right Format:
- CSV (Comma-Separated Values): The most common, simplest format. It’s just a spreadsheet and is probably applicable to most of your needs. It can easily be imported into Excel or Google Sheets.
- JSON (JavaScript Object Notation): The better format for web-scraped hierarchical data. A great example is a single profile’s “Experience” section. This likely has many jobs and each job has its own title, company and dates. A JSON array can hold that hierarchical structure in a cleanly-defined format far better than a flat file like a CSV can.
- Database: For very large scale and almost ongoing scraping projects, data stored to a database (PostgreSQL, MySQL, etc.) would be the most versatile and resilient solution and also enable you to use the searching, indexing and management capabilities of Database systems.
- Clean and Normalize Your Data: As brought up in the challenges section, data cleaning and normalization is mandatory. Raw web-scraped data is not clean. You will need a post-process step to normalize fields, clean up typos and set all date fields to a consistent date format. Normalized data is a higher quality product that allows you to easily analyze data too.
- Include Metadata: You should always save metadata with your scraped data. Metadata should include:
- scrape_timestamp: The exact date and time you scraped the data. LinkedIn data changes so knowing when your data was current is important.
- source_url: The URL for the profile or company page you scraped. This preserves an audit trail and gives you an easy way to go back to the source.
- Be Respectful and Ethical: Be a good data citizen. Don’t scrape sensitive personal information. Pay attention to data privacy laws, such as GDPR and CCPA. Make sure you securely store the data, as well as only using it for its approved, legitimate purpose. Don’t re-publish large datasets of personal information.
Conclusion: knowledge of how to web scrape LinkedIn
Acquiring the knowledge of how to web scrape LinkedIn can be an incredible asset to both your business and/or your research. With an understanding of how to choose between the tools at your disposal, including simple Chrome extensions to serious Python processes, you can determine the best path forward.
Ultimately, the key to successfully scraping LinkedIn is not purely the technical execution, is rather a matter of how to do so in a smart, responsible way. It is important to plan, clearly outline your data needs, do so with small steps first, and, most importantly, use techniques that mitigate detection. This will include using rotating residential proxies, restricting your speed, and adding randomization to your actions.
It is to your advantage to behave humanely. While the law may side with a scraper of public data, the LinkedIn user agreement will not request that scraping socially be smart in what data you are accessing, and how close you get to disrupting the platform, and ultimately get your account banned.
With patience and the right tools and a plan, you may be able to make LinkedIn a powerful automated line of information for corporate and professional intelligence.
FAQs for How to Web Scrape LinkedIn
1. Is it possible to pull data from LinkedIn without my account being suspended?
Yes, it can be done, but you need to be very cautious! There is a risk of suspension. You will want to scrape as slowly and human-like as is practical, use quality rotating residential proxies, randomize your activity, and limit the total profiles scraped from one account each day. Some accounts have reported being able to scrape hundreds a day without issue, but I have seen accounts get suspended for scraping as little as 10 a day! Never scrape thousands of profiles in a day; that’s a sure way to cause a suspension!
2. What is the best tool for a beginner to use to scrape LinkedIn?
If you are a complete beginner and cannot program, use a no-code web scraping LinkedIn interface that allows you to simply point and click on the data you want to pull, and the action is typically much more intuitive than when writing code!
3. How many profiles can I scrape from LinkedIn in a day?
There is no official limit, but as a rule of thumb, keep your profile visits to no more than 100-200 per day per LinkedIn account. With company pages, you can probably visit more. Going over this number, especially with newer accounts or accounts that don’t have a lot of activity, puts you at risk with LinkedIn security algorithms, and the risk of a temporary restriction or permanent ban goes up significantly. Slow and steady wins the race.
4. Can I scrape the email addresses of LinkedIn users?
This is a gray area and generally not advisable. Email addresses are private information of LinkedIn users and are not publicly visible on the user profile unless the user explicitly makes them visible. Digging deeper to find ways to expose private email addresses is a clear violation of privacy and violates the ethical principles of data scraping. Stick to scraping publicly available professional data such as job titles, experience, and skills.
5. Do I need to use a special “scraping” LinkedIn account?
It is highly recommended to use a dedicated LinkedIn account for scraping purposes. You should not use your personal, primary LinkedIn account. This dedicated account should be “warmed up” over time, meaning you should use it like a real person for a few weeks by adding connections, posting updates, and engaging with content before you begin any scraping activity. This makes the account look more legitimate and less likely to be flagged.




