
Nowadays, “data is the new oil” is a common phrase to illustrate the economic significance of data. However, data that is unstructured and siloed is akin to crude oil; it’s worthless when raw, hard to move, and seemingly impossible to break down and use. In order to utilize the raw resource we call data, organizations need to go through a very sophisticated process called data integration.
If you ever wondered, “What is data integration?” and how it has become the foundation of business intelligence today, then you are in the right place. Data integration is no longer a technical exercise to be applied just by IT teams. It has become a business strategy that drives a company’s viability, competitiveness, and ability to innovate and service its clients.
A company without a coherent approach for effectively integrating data from different sources is essentially a ship without a rudder and will end up operating in the dark, utilizing incomplete and/or in capability of gaining a complete picture of its customers and operational measures. This guide will provide the fundamental components of data integration, its benefits, processes, and a glimpse into future practices.
Table of Contents
What Is Data Integration?
Essentially, data integration is the act of bringing together data from various sources, applications, and formats into one consolidated and coherent view. The goal is to provide users, whether they are business analysts, data scientists, or operational members, with a singular dataset that is both full and consistent.
Consider a large, global retailer. They may obtain customer data from a variety of systems: sales history may live in an ERP (Enterprise Resource Planning) tool; website behavior may be captured in a web analytics tool; customer service tickets may live in a CRM (Customer Relationship Management) tool; and logistics data may be captured in a supply chain tool. Each one of these systems runs independently of each other and builds internals of both processes and thus creates data “silos.”
Data integration seeks to eliminate these silos so that when a data analyst queries the system, they are able to see a holistic and accurate representation of the customer—even a fairly recent purchase, an outgoing support call, last week’s browsing habits and so on. When we speak of what is a data integration strategy, we are referring a methodology, tools and architecture that are intended to allow for this unified view. What are top data integration tools?
We are trying to digest this process into a few sub-tasks, such as the following four:
- Ingestion: Transitioning of data from the production source to a staging or target environment.
- Cleansing: Identifying and rectifying mistakes, irregularities, and inaccuracies of data.
- Transforming: Changing the structured format of the data in the way that the business and the target system require.
- Loading: Delivering the extracted, unified data to a central location (typically to a data warehouse, data lake, or data Lakehouse).
The Importance of Data Integration in Today’s Data-Driven World
In today’s data-driven world, a key competitive advantage has become the ability to quickly access high-quality data in one consolidated source. However, the question of what is meant by data integration is not just technical; it’s about establishing a “single source of truth.”
Organizations around the world depend on integrated data as their competitive advantage. Without a single source of truth (in other words, integrated data) business units involve themselves with unaligned measures or “numbers” which lead to conflicts between departments, longer decision cycles, and missed opportunities.
For example, marketing may evaluate customer segments analyzing data from their SaaS tools, while finance may use transaction records extracted from their legacy systems. These two datasets may not be aligned and therefore high-level insights into profitability will not be aligned, which will impact strategic alignment.
Furthermore, by integrating datasets, every business unit (sales, operations, and human resources) will have access to the same accurate and trusted dataset. Consistency across business units is critical, especially with regards to reliable reporting, regulatory compliance, and to have the confidence to execute a business strategy.
Integrating Resume Parsing with the magical api
In the field of recruitment and talent acquisition, the power to quickly process and analyze unstructured text data (including resumes and job descriptions) is critical. Specialized data integration tools and APIs are where this capability flourishes.
Magical Resume Parser
Discover the powerful capabilities of the Magical Resume Parser and explore the various options available to streamline your hiring process, optimize candidate selection, and enhance recruitment efficiency.
magical api is one such service that pushes in AI careers and data insights through its specialization to extracting and structuring information from publicly-accessible web/third-party sources, and documents. Their Magical Resume and Magical Data product lines are strong use cases for API-driven data integration.
For a hiring platform, the steps of integrating candidate data usually include the following:
- Data Extraction: Candidates upload raw resumés (PDF, DOCX).
- Data Parsing and Structuring: Using a powerful tool such as the Resume Parser from magical api, the disorganized text is immediately changed into clean, structured JSON or XML data. The structured data is so important for loading into a database.
- Data Enrichment and Linking: The system may then use other products or services that access public information on candidates like the Linkedin Profile Scraper or Linkedin Company Scraper to enrich the structured resume data for the candidate with public professional data and give recruiters further insight into the candidate.
- Data Integration: Then the structured and/or enriched data automatically loads into the organization’s Applicant Tracking System (ATS) or HRIS (Human Resources Information System).
Integrating Resume Parsing with an agency API like magical api mitigates manual data entry, ensures structured data quality is high, and helps recruitment teams focus on the quality of the candidates and not administrative data entry. This is a classic case of how API-based data integration can streamline core business processes.
How Data Integration Improves Decision-Making and Efficiency
The direct impact of data integration is felt most profoundly in two areas: the quality of decisions and the efficiency of operations.
Improved Decision Quality
When data is integrated, it provides context for your decisions. If a sales manager sees a number on a set of monthly revenue figures, they have one metric in front of them. If they combine that revenue figure with customer churn rates, product inventory levels, and regional market trends, they gain a 360-degree view of performance.
This larger context allows them to move from basic reporting (“What happened?”) to advanced analysis (“Why did it happen?”) to forecasting (“What happens next?”). Seamless integration across disparate metrics (for example, coupling demographics of the applicants from the Resume Parser tool to successful employee retention) is key to smarter decisions. With integrated data, HR teams can make more informed, data-driven hiring decisions in an efficient manner.
Improved Operational Efficiency
Manual data manipulation and workflows (exporting spreadsheets, running VLOOKUPs, cleaning up the formats) are labor intensive and potentially create errors. Organizations drive down fixed time associated with preparing data, and increase time available for analysis, by automating the extraction, transformation, and loading of data through an integration pipeline.
Additionally, with a single pool of data, you can drive streamlined workflows across functional boundaries. For instance, if you sync the customer data in your CRM and inventory system, a seller would be able to check your stock in real time as they are making a sale to your customer, at that moment, enabling a better experience for the customer and eliminating fulfillment errors.
Common Data Integration Methods and Techniques Explained
Various approaches exist in the technology landscape to distribute unified data. The choice of approach will vary, mostly based on volume, velocity, and latency requirements for the organization.
1. Extract, Transform, Load (ETL)
This is a tried-and-true, method that has been used for many decades.
- Extract: Data is taken from source systems.
- Transform: Data is validated, standardized, aggregated, and matched to the schema before leaving the staging area.
- Load: The clean, transformed data is loaded into a data warehouse.
ETL works well for building highly structured data warehouses where the focus is to get high-quality data into the warehouse for business intelligence and standardized reporting.
2. Extract, Load, Transform (ELT)
This is the modern-day approach, enabled by the transformation of cloud data warehousing and data lakes.
- Extract: Data is taken from source systems.
- Load: The raw data is immediately loaded into the cloud data warehouse or data lake.
- Transform: The data is transformed in the target system, utilizing the incredible computing power of the cloud platform.
ELT is faster for ingestion and also offers more flexibility because data analysts can perform many transformations of the raw data for different use cases without the need to re-ingest.
3. Data Virtualization (Data Federation)
Data virtualization is a capability in which data remains in its original source, but a software layer gives a consistent, virtual view of the data. When a user queries this virtual layer, the system translates the query, pulls the necessary data into memory in real-time from various sources, and delivers the result without physically moving or copying the data. This is critical in the case of accessing live, constantly changing data without the burden of storing the replicated data.
4. Data Streaming and Real-Time Integration
This process continuously processes and examines data while it is being generated, typically with technologies such as Apache Kafka. In a streaming model, data is no longer processed in batches (such as traditional ETL), but data is treated as a continuous stream of data for analytic purposes, allowing for a real-time analysis and immediate action, which is critical to fraud detection, monitoring of IoT devices, or applying real-time personalization to a website.
Choosing the Right Data Integration Architecture: ETL vs. ELT vs. Virtualization
Selecting the correct architecture is perhaps the most critical strategic decision in designing a data strategy. The choice hinges on three main factors: cost, speed, and flexibility.
| Feature | ETL (Traditional) | ELT (Modern) | Data Virtualization |
| Transformation Location | Staging server/Integration server | Target data warehouse/lake | Virtualization layer (No movement) |
| Best For | Structured data, legacy systems, strict data quality requirements upon arrival. | Big data, cloud data warehouses, unstructured/semi-structured data, flexibility. | Real-time queries, highly dispersed data, reduced storage cost, low latency. |
| Speed/Latency | Higher latency due to transformation time before loading (batch processing). | Lower ingestion latency, transformation speed depends on cloud warehouse compute. | Lowest latency (near real-time access to source data). |
| Data Storage | Requires separate staging area and destination storage. | Requires only destination storage (data lake/warehouse). | Requires no new storage for the integrated view. |
For many businesses, a hybrid approach is the reality. High-volume transactional data might utilize ELT into a cloud data lake, while sensitive or legacy data might use traditional ETL into a managed data warehouse. Data virtualization, meanwhile, can be layered on top to provide real-time access to operational systems when necessary, combining the strengths of multiple architectures.
Key Benefits of Implementing a Data Integration Strategy
The value proposition of robust Data integration is transformative, changing the equation from not just data consolidation, but true business impact.
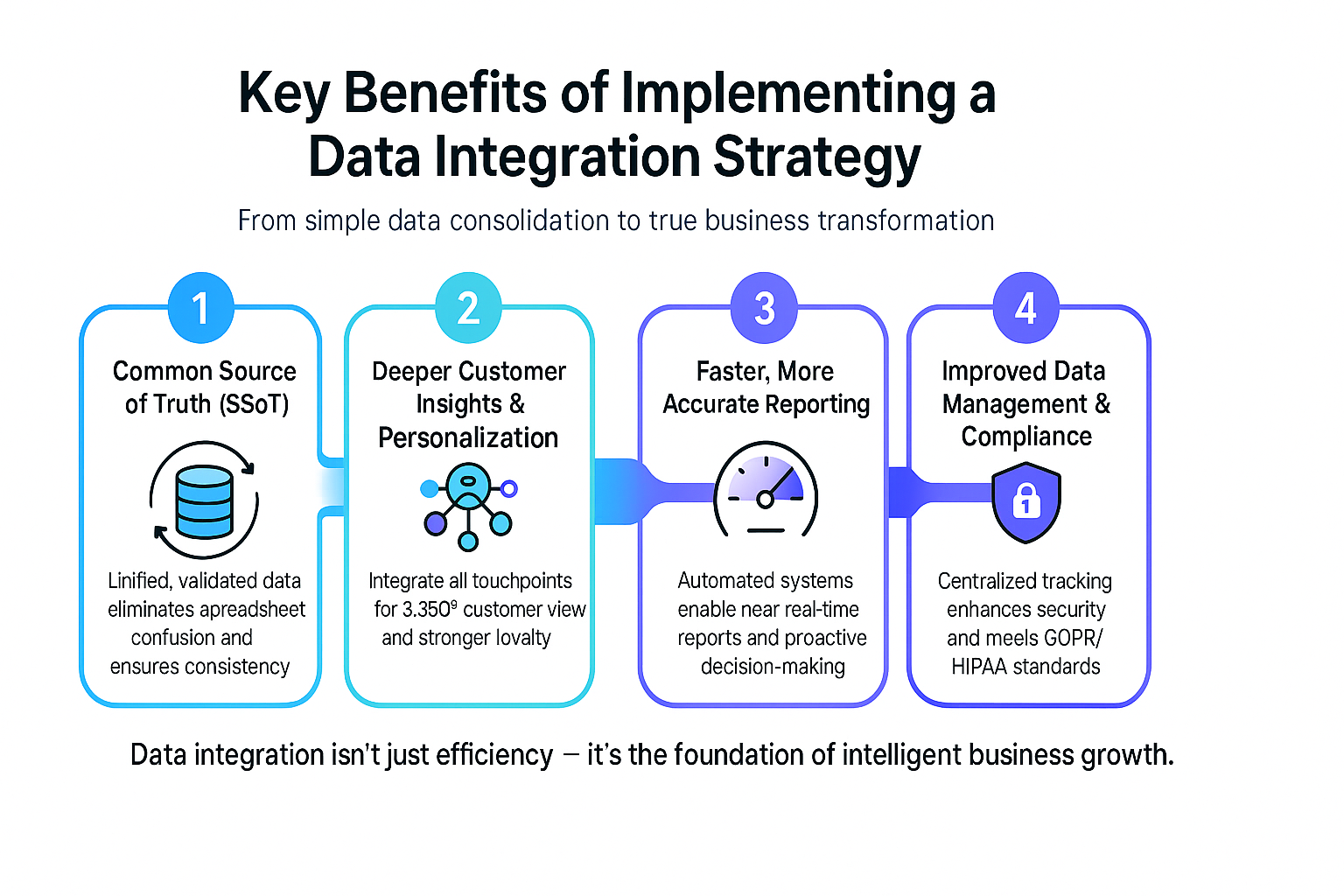
1. All Departments Have a Common Source of Truth (SSoT)
This is the holy grail of data management. Once one version of a truth data set (validated) is established, reports are easier to create consistently, inclined to use the same metrics, and speak confidently about what the business leads the company into action around. No more “spreadsheet confusion” as each person gathering the data pull it at slightly different times and have different definitions, confuse the reporting.
2. More Profound insights by the Customer and Personalization
By integrating data captured anywhere there is a customer touchpoint (website visit – potentially using similar resources as a How to Use a Web Scraper Chrome Extension…for example), CRM information, purchase history, social media interactions, you can build a complete Customer 360 representative profile.
This leads to hyper-personalization, where the business can anticipate customer needs to make current and/or timely and relevant offers, increasing overall customer loyalty and lifetime value immensely.
3. Speedier and More Precise Reporting
Because of the automation found within an integrated system, reports that used to take days to complete are available in minutes or hours. The finance team can perform fast monthly financial closes while the operations team can view key performance indicators (KPIs) immediately, and act before the need to respond occurs.
4. Better Data Management and Compliance
Having a centralized and integrated system allows you to track where each data element comes from, who owns it, and how it moves, and those data provenance traces are essential to demonstrating regulatory compliance (such as GDPR or HIPAA) and maintaining data security and consistency across all systems.
Best Practices for Ensuring Data Quality and Governance in Integrated Systems
A successful data integration project is not just about moving data, it is about moving good data. Poor data quality can infect the entire analytical process, transforming a costly data integration effort into a much more costly failure. Data governance and data quality practices are fundamental to any successful strategy.
1. Data Profiling and Cleansing at the Source
Before data is moved, it should be profiled and evaluated to understand what its current state is; how many missing values, inconsistent formats or duplicates are present. Data cleansing should always be considered part of the transformation step of the integration, where fields are standardized, inconsistencies are corrected, and redundant records are culled. Using candidate data as an example, the data you import via a Resume Parser should ensure that names, dates, and experience fields are all standardized, and accurately categorized across the data set.
2. Defining Clear Data Accountability and Data Stewardship
Data governance involves determining who is responsible for the accuracy, clarity, and access for specific data sets. Data stewardship is a non-technical role that focuses on adherence to organizational policy and accuracy of data quality. A data steward ensures that a business definition, such as “Active Customer” or “Successful Sale,” is used consistently across all integrated systems.
3. Establish a Centralized Data Catalog
A data catalog serves as a library for all data that has been integrated, featuring metadata, data lineage, and business definitions. This level of transparency allows end users to identify what data is accessible and its trustworthiness, reducing the risk of misuse of data and building confidence in insights.
LinkedIn Profile Scraper - Profile Data
Discover everything you need to know about LinkedIn Profile Scraper , including its features, benefits, and the different options available to help you extract valuable professional data efficiently.
Challenges of Data Integration, and How to Overcome Them
Despite its benefits, data integration is not without hurdles. Organizations must be prepared to face and mitigate complex technical and organizational challenges.
1. The Three Vs: Volume, Velocity, and Variety
Integrating big data is challenging due to its large size (Volume), its speed (Velocity–especially for streaming data), and its different formats (Variety, i.e., structured, semi-structured, and unstructured). Such challenges require us to build cloud-native, horizontally scalable platforms designed for massive parallel processing, using an ELT architecture often times.
2. Integrate Legacy and Heterogeneous Systems
Many organizations rely on on-premise systems established decades ago, and have proprietary data formats and have no modern APIs. Integrating and exchanging data with these legacy systems to get to the modern cloud systems is a significant engineering challenge, oftentimes requiring custom integrated middleware or a custom connector to bridge the technology gap and bring their data over effectively.
3. Discrepancies in Data Semantics and Definition
However, the successful transfer of data may not be useful, because different source systems may meaningfully use the same field name, for different features and purposes, or give different information for a similar concept. For example, one system records when a prospective client is a “Lead,” and another system records when a prospective client is a “Contact.”
In these situations, we consider it to be the challenge of integration meaning. A best practice is to develop a common understanding of the logical data model of the source systems by mapping fields and definitions to a common logical field model, during the transformation phase.
Top Data Integration Tools and Platforms You Should Know
Numerous data integration tools are separated by either open-source frameworks or enterprise-grade platforms. It will depend on the technical expertise of the user, the complexity of the data sources being integrated, and/or cloud vs. on-premise destination.
Cloud-Native ETL/ELT Platforms:
You want ETL/ELT solutions that can be deployed or easily connected to a cloud data warehouse (such as Snowflake, Google BigQuery, or Amazon Redshift). They are built for scalability and performance. Platforms like Fivetran, Stitch, or Informatica Intelligent Data Management Cloud (IDMC) are cloud-native, and come with ready-to-go solutions between hundreds of pre-built connectors to get data out of the standard SaaS applications.
Open-Sourced Frameworks:
For organizations with high levels of technical expertise, highly customized integration, or open-source variances, then you want to go this route. Apache Kafka is a standard in data streaming, or other tools like Airbyte or Meltano give open-source variances of similar ETL/ELT Pipelines, for teams of engineers that wish to fully customize their integration scripts.
Data Virtualization Platforms:
Finally, you will want to consider denodo or tibco data virtualization–Apps/solutions similar to this work as data virtualisation apps to provide that single, logical view of data without ever physically moving the data around, which is critical for organizations with higher levels of latency or those vertically bound by data sovereignty.
Data Integration in the Era of AI and Machine Learning
The connection between AI Data Integration and machine learning is circular because AI needs vast quantities of clean, integrated data to work, and AI is changing how data integration is done.
AI-Driven Data Quality and Mapping
AI and ML algorithms are believed to be included in integration platforms for automating manual tasks. For example, AI can be leveraged to recognize patterns in unstructured and semi-structured data, recommend transformation rules, and predict impending data quality issues. This technique is especially pertinent when classifying and standardizing data fields from hundreds of sources.
Real-Time Data for ML Models
Machine Learning models especially those for real-time risk assessment, anomaly detection, dynamic pricing, etc. require continuous streams of integrated data.
Therefore, fast, reliable data integration pipelines (like streaming architectures) is critical when it comes to provide models with high-velocity, low-latency data required for quality predictions and instantaneous actions. Consider a company offering a Resume Score service, that requires continuous integration from multiple career data sources to train and continuously improve the predictive AI models behind its service.
Real-World Use Cases: How Companies Thrive with Data Integration
Data integration is not an abstract concept; it drives measurable, real-world business outcomes across every industry.
Retail and E-commerce: Inventory and Customer 360
One large e-commerce company combines the sales data (in real-time) from their e-commerce platform and warehouse inventory levels from their warehouse management system (WMS), plus geolocation from their customer relationship management (CRM) system and other information about where their customers are based. This provides the company with a 360-degree view that enables them to:
o Dynamically optimize pricing based on local demand, or local stock levels; o Offer accurate (and real-time, based) delivery estimates; o Make website recommendations based on the history of a customer’s full purchase and browsing history (which can include information gathered using scraping techniques).
Financial Services: Fraud Detection
With a bank processing millions of transactions each day—most requiring the bank’s system to ascertain if fraud is occurring within milliseconds, streaming data integration (streaming data from each of the banks transaction feeds, authentication/login history, geolocation data, and customer profile) is paramount.
Streaming data integration allows the banks AI model to score all transactions in real-time to see what risk exists if any. Thus, the speed is pertinent and valuable to knowing whether to block the fraudulent transfer prior to the transaction being accepted.
Healthcare: Patient Interoperability
Meanwhile, hospitals/clinics are applying data integration by combining electronic health records (EHR) data with medical device data, as well as billing systems data and lab results, creating an electronic healing record of the patient, allowing the doctor a comprehensive view of the patient’s entire medical history during the time of care.
Not only does this mean the doctor has an up-to-date view of the patient’s health information, but the doctor is assigned the role of decision-making and attention during the visit. This type of data integration allows for much faster diagnoses, leading to better patient outcomes and reducing the risk of medical errors.
The Future of Data Integration: Trends Shaping the Next Decade
The evolution towards data integration is one of increasing automation, democratization, and real-time capabilities. Some major trends are just starting that will influence the next decade in the field.
1. Data Mesh
Data Mesh is a decentralized architecture that is domain-oriented, rather than a centralized data warehouse managed by a single team or consolidated with many teams. Domain teams are responsible for treating data as a “product” (e.g., Sales Data, Marketing Data) and develop the integration using consistent data APIs, allowing business units to determine their own ownership and speed.
2. Reverse ETL
Traditional ETL engages a process of loading data into the central data warehouse for analytical purposes. Reverse ETL is the process of moving finalized, derived insights and derived intelligence out of the data warehouse and introduced back into operating SaaS applications (like CRM, marketing automation, or customer support tools). This creates a complete loop that allows analytic insights to generate immediate operational actions.
3. Generative AI for Data Transformation
An emerging wave of tools leveraging generative AI capabilities to automatically create data transformation code (e.g., SQL or Python scripts) based on simple natural language prompts or by observing data patterns will greatly simplify the process and allow for even more democratization of integration capabilities. Non-engineers will be able to create complex data pipelines with relative ease..
Conclusion: Data integration
What is data integration? It is the base process that affords the modern, intelligent enterprise. It makes data that is distributed, disparate, and disconnected into a uniform, conformed, and reusable asset; the one source of truth that is needed to be competitive and gain a competitive advantage. Data integration approaches based on traditional ETL, to modern ELT, to powerful API platforms like magical api in between have many methods and are sophisticated.
By making a thoughtful investment in a data integration strategy — one that considers not just the technology, but data quality, governance, and architecture, your organization can ensure it is not just collecting data, but putting that data to work well into the future to drive efficiency, improve customer experience, and produce successful data-driven outcomes.
Common Questions for Data integration
1. What distinguishes ETL from ELT?
The main distinction lies in the timing of the transformation step. ETL (Extract, Transform, and Load) implies that data is cleaned and restructured on a separate staging server before it is loaded into the target data warehouse. ELT (Extract, Load, Transform) means that raw data is loaded directly into the target cloud data warehouse or data lake, and then transformation occurs in the cloud data warehouse or cloud data lake after loading, where powerful compute resources are available in the destination system.
2. How can data integration promote data governance?
Data integration is a contributor to data governance because data integration provides a centralized and managed flow of all enterprise data. By defining specific transformation rules and loading data into one repository, it allows organizations to effectively manage and track data lineage, enforce data quality standards (data cleansing), and consistently apply security and compliance policies to the entire dataset.
3. Am I able to utilize web scraping tools as part of a data integration pipeline?
Yes. Web scraping tools, especially those that scrape data from publicly available webpages, are often employed as source systems within a data integration pipeline. After a tool scrapes, for instance, using a Web Scraper Chrome Extension that tracks competitor pricing, the unstructured data must be integrated. This means the raw scrape data is typically extracted, cleaned, structured, and then loaded together with internal data (sales data) for a unified analysis view for business intelligence.
4. Is data integration synonymous with data migration?
No, data integration and data migration are not synonymous. Data migration refers to the movement of data from a source data system or environment to a target system, typically as a one-time event, such as when a system gets upgraded or replaced every so often. In contrast, data integration is a continuous and ongoing activity that provides an up-to-date view of data which is synchronized and harmonized to data in a variety of disparate sources (to an internal source system or other).



